
ACGR in CxPortal: Operationalizing Regional Failover in Amazon Connect


Regional failover in Amazon Connect is an infrastructure capability, but a regional disruption is felt immediately on the contact center floor. Calls drop, contacts route incorrectly, and agents lose the ability to log in. Downtime carries consequences that directly impact customer interactions, SLA commitments, executive visibility, and brand trust.
Amazon Connect Global Resiliency (ACGR) provides the foundation for multi-region redundancy through traffic distribution groups that manage agent and telephony failover. However, infrastructure capability alone does not ensure operational readiness.
Today, initiating failover requires access to the AWS Management Console or CLI. In many organizations, access resides with infrastructure or cloud engineering teams rather than contact center operations. As a result, the team that detects the disruption is often not the team authorized to execute failover.
This separation introduces delay at the very moment speed matters most.
ACGR in CxPortal closes this operational gap by placing failover execution directly in the hands of contact center operations. As a result, resiliency shifts from an engineering procedure to an embedded operational capability.
What Changes with ACGR in CxPortal
ACGR in CxPortal builds on the underlying Amazon Connect Global Resiliency framework by introducing an operational control layer designed for contact center teams. Instead of managing resiliency across multiple AWS interfaces, organizations can centralize configuration, execution, and visibility within a single operational environment.
This environment brings together playbook configuration, traffic distribution management, and real-time regional visibility.
With ACGR in CxPortal, resiliency becomes structured, governed, and repeatable.
How It Works
ACGR in CxPortal operationalizes resiliency across three phases: preparation before an incident, execution during an incident, and controlled recovery after.
Prepare
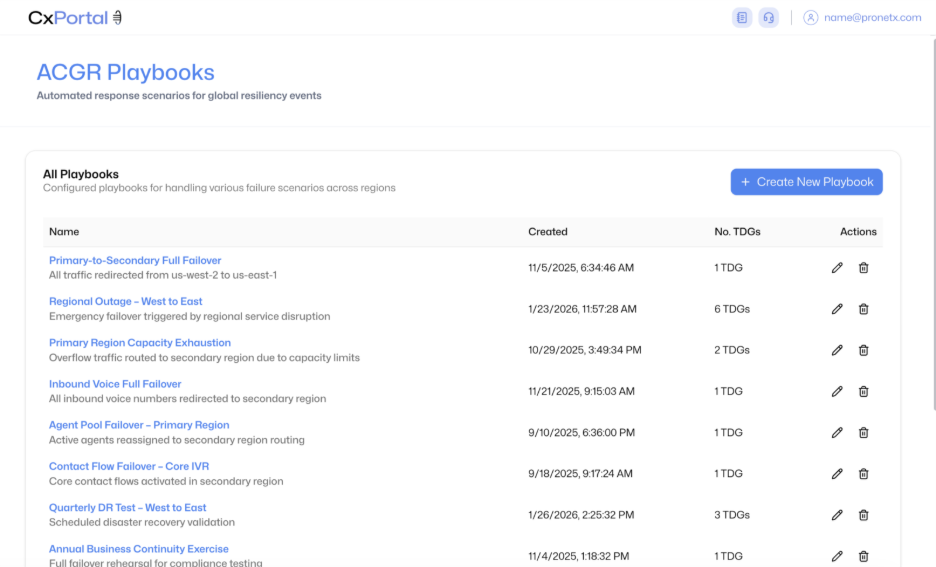
Before an incident occurs, disruption scenarios are formalized as playbooks that define how traffic should redistribute across regions. Agents and phone numbers are organized into traffic distribution groups, with primary and secondary routing paths established in advance.
Each playbook is validated during planned maintenance windows to confirm expected behavior. As a result, failover execution follows a controlled and repeatable process rather than an improvised response under pressure.
Execute

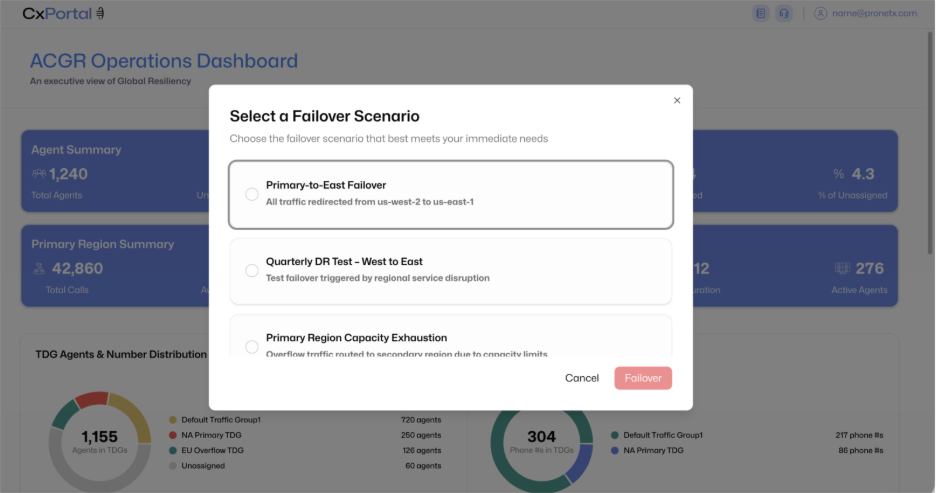
During a regional impairment, health status is monitored directly within CxPortal. When action is required, the appropriate playbook is selected, scope is reviewed, and execution is confirmed.
Traffic shifts automatically to the designated backup region without manual reconfiguration across systems or cross-team escalation. What might otherwise require hours of coordination can be executed within minutes as part of the operational workflow.
Recover
Once stability is restored, traffic returns to the primary region in controlled stages. Distribution percentages can be adjusted gradually while monitoring queue performance and agent availability, reducing the risk of overloading the restored region.
Execution history and activity timelines are reviewed to refine playbooks and strengthen future response readiness.
Visibility and Governance
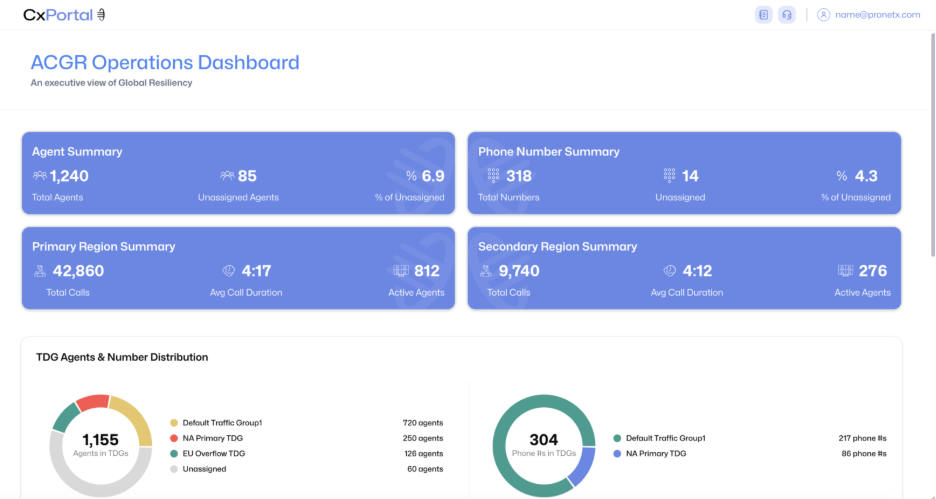
Throughout the event lifecycle, CxPortal provides visibility into:
- Regional health status
- Recently executed playbooks with timestamps
- Current traffic distribution across active regions
- Historical records of traffic patterns and failover activity
This level of visibility gives teams a clear record of what occurred, when it occurred, and how traffic was redistributed. It provides clarity during incidents and accountability afterward.
Outcomes
Service continuity. Traffic routes to backup regions based on predefined playbooks, limiting exposure during regional impairments.
Faster recovery time. What might otherwise require hours of coordination can be executed within minutes, reducing the duration and impact of service disruption.
Predictable execution. Failover procedures are configured, tested, and validated before an event occurs, so teams follow a known path during a disruption.
Reduced coordination overhead. The team with real-time operational context executes directly, without escalation paths or cross-team dependencies.
Consistent customer experience. Customers and agents experience continuity without visible disruption, dropped contacts, or degraded routing.
Getting Started
Failover events are infrequent, but the cost of a slow response increases with every minute of dropped contacts and SLA exposure. ACGR in CxPortal gives operations teams the ability to prepare for that moment and act on it immediately.
.svg)
.svg)